As organizations increasingly adopt Large Language Models (LLMs) into their operations, managing costs while maintaining performance becomes crucial. The rapid scaling of AI applications can lead to unexpectedly high expenses if not properly monitored and optimized. This blog explores the five most critical metrics that organizations should track to optimize their LLM costs effectively.
1. Cost Per Token
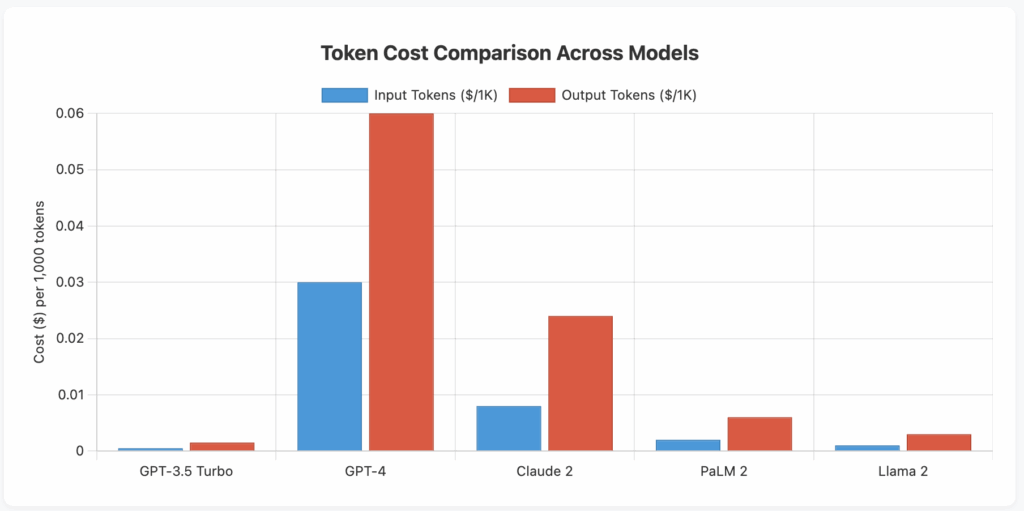
What it measures: Cost per token tracks the expense incurred for processing each token (roughly 3/4 of a word) through your LLM. This includes both input tokens (prompts) and output tokens (responses), which are often priced differently. It provides a granular view of your LLM expenses at the most fundamental unit of measurement.
Why it matters: Understanding your cost per token is essential because it directly correlates with your usage patterns and helps identify opportunities for optimization. Different models have vastly different token pricing, and even within the same model, input and output tokens may have different costs. This metric helps you make informed decisions about model selection and usage patterns.
Key actions:
- Compare token costs across different LLM providers and models to find the most cost-effective option for your use case
- Optimize prompt engineering to reduce unnecessary tokens while maintaining quality
- Implement token limits and budgets for different applications or teams
- Consider using smaller, more efficient models for simpler tasks
- Cache frequently used responses to avoid reprocessing identical queries
2. Request Volume and Frequency
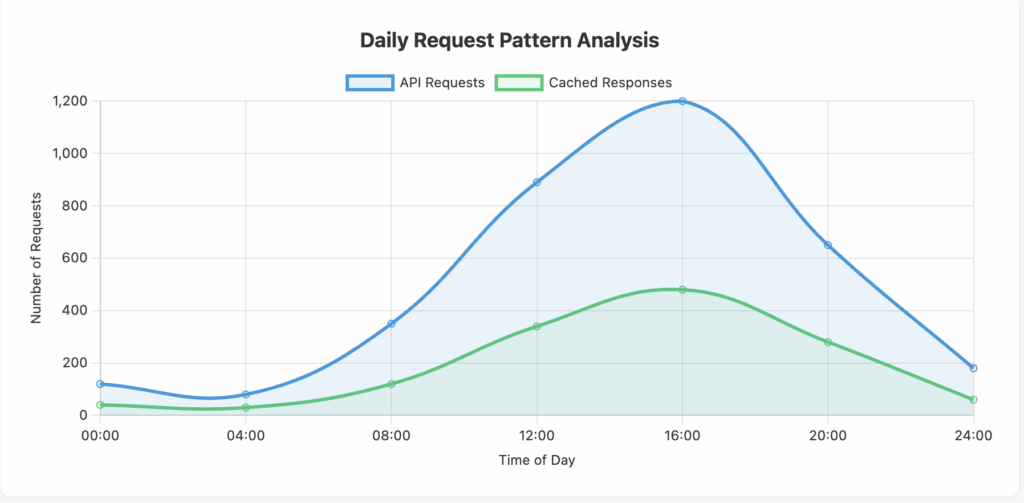
What it measures: This metric tracks the total number of API calls or requests made to your LLM service over time, including patterns of usage throughout the day, week, or month. It encompasses both successful requests and failed attempts, providing insights into usage patterns and potential inefficiencies.
Why it matters: Request volume directly impacts your costs, especially if you’re charged per API call in addition to token usage. Understanding request patterns helps identify peak usage times, redundant calls, and opportunities for batch processing. It also reveals whether your applications are making unnecessary or duplicate requests that could be eliminated.
Key actions:
- Implement request batching to process multiple queries in a single API call where possible
- Set up intelligent caching mechanisms to avoid repeated identical requests
- Establish rate limiting to prevent runaway costs from bugs or misconfigurations
- Analyze usage patterns to identify and eliminate redundant or unnecessary requests
- Schedule non-urgent requests during off-peak times if your provider offers time-based pricing
3. Model Performance Efficiency
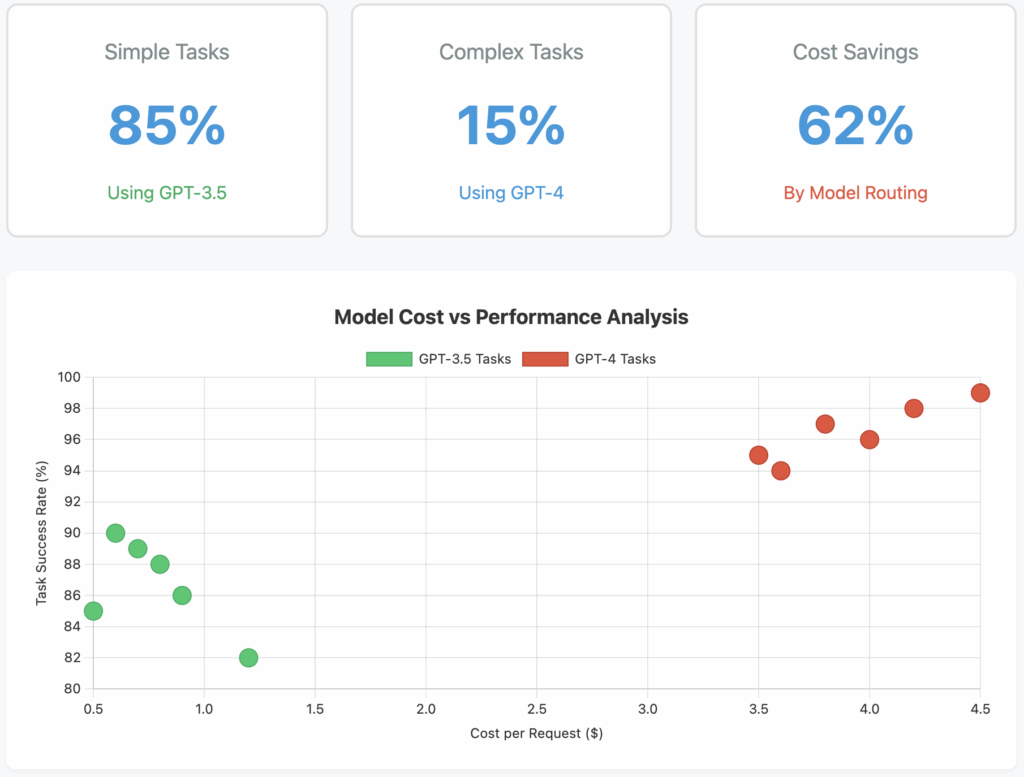
What it measures: Model performance efficiency measures the relationship between the computational resources consumed and the quality of outputs produced. This includes metrics like latency, throughput, accuracy rates, and the percentage of responses that meet quality thresholds without requiring regeneration or human intervention.
Why it matters: Using an overpowered model for simple tasks wastes resources and money, while using an inadequate model may require multiple attempts or human correction, ultimately costing more. This metric helps ensure you’re using the right model for each task, balancing cost with performance requirements.
Key actions:
- Implement A/B testing to compare different models for specific use cases
- Create a model routing system that directs queries to appropriate models based on complexity
- Monitor task completion rates and accuracy to ensure chosen models meet requirements
- Regularly evaluate newer, more efficient models as they become available
- Document performance requirements for different use cases to guide model selection
4. Token Utilization Rate
What it measures: Token utilization rate measures how efficiently you’re using the tokens you’re paying for. This includes analyzing the ratio of meaningful content to padding or unnecessary verbosity in both prompts and responses, as well as tracking wasted tokens from failed requests or discarded outputs.
Why it matters: Poor token utilization directly translates to wasted money. Many organizations unknowingly pay for tokens that don’t contribute to their desired outcomes, whether through verbose prompts, unnecessarily detailed responses, or failed requests. Optimizing token utilization can significantly reduce costs without impacting functionality.
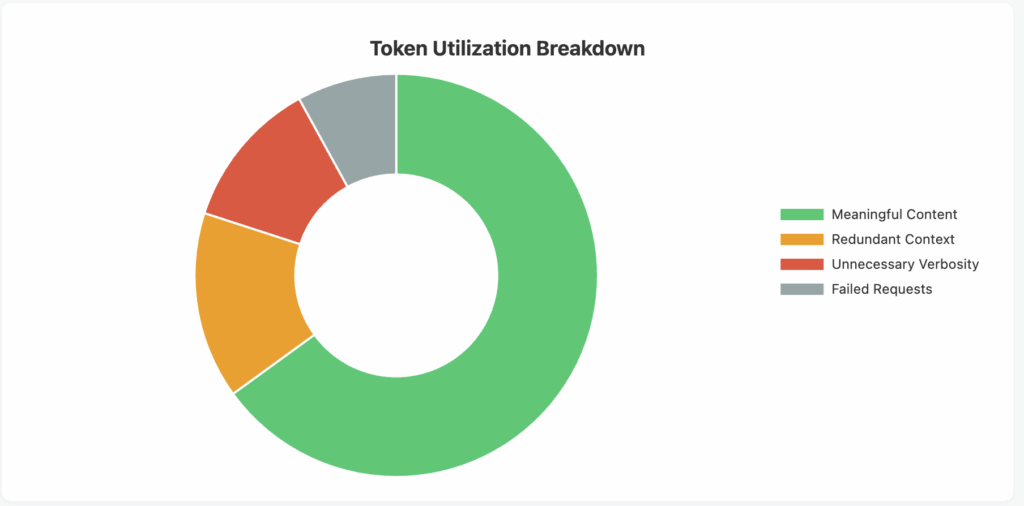
Key actions:
- Refine prompts to be concise while maintaining clarity and context
- Implement response length controls appropriate to each use case
- Use prompt templates and variables to avoid repetitive content
- Monitor and minimize failed requests that consume tokens without providing value
- Train teams on efficient prompt engineering techniques
5. Cost Per Business Outcome
What it measures: This metric ties LLM costs to specific business results, such as cost per customer query resolved, cost per document processed, or cost per sale influenced by AI assistance. It provides a holistic view of LLM ROI by connecting technical metrics to business value.
Why it matters: While technical metrics are important, ultimately what matters is whether your LLM investment delivers business value efficiently. This metric helps justify LLM expenses to stakeholders and identifies which use cases provide the best return on investment. It also highlights areas where costs may be too high relative to the value delivered.
Key actions:
- Define clear business outcomes for each LLM use case
- Implement tracking to connect LLM usage to business results
- Regularly review and optimize use cases with poor cost-to-outcome ratios
- Prioritize investment in high-ROI applications
- Create dashboards that visualize the relationship between LLM costs and business value
Conclusion
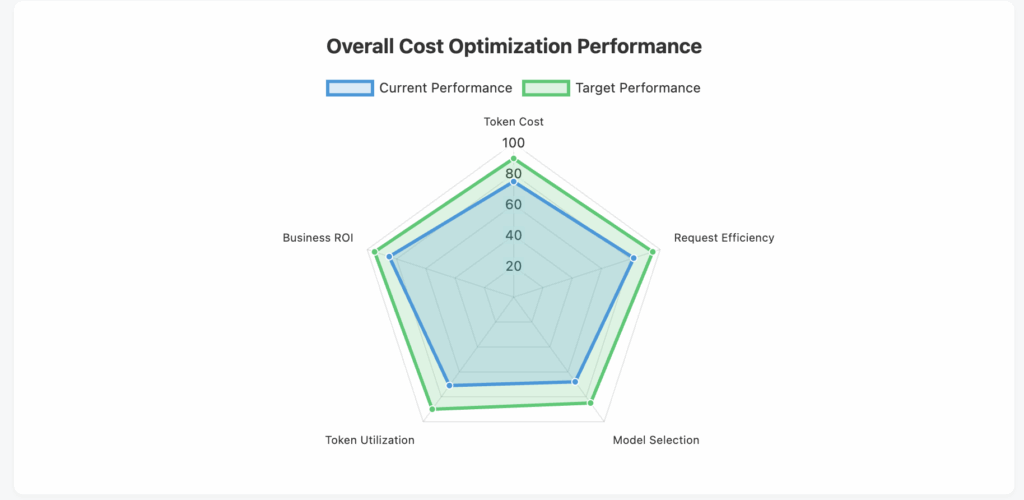
Optimizing LLM costs requires a comprehensive approach that goes beyond simply choosing the cheapest model. By carefully monitoring these five key metrics—cost per token, request volume and frequency, model performance efficiency, token utilization rate, and cost per business outcome—organizations can build a sustainable and cost-effective LLM strategy.
The key to success lies in establishing baseline measurements, setting optimization targets, and continuously monitoring and adjusting your approach. Remember that cost optimization shouldn’t come at the expense of quality or business value. Instead, it should focus on eliminating waste, improving efficiency, and ensuring that every dollar spent on LLM services contributes meaningfully to your organization’s goals.
As the LLM landscape continues to evolve with new models and pricing structures, maintaining visibility into these metrics will help you adapt quickly and make informed decisions that balance cost, performance, and business value.